
Table of Contents
Pico-Banana-400K: What’s Inside Apple’s 400K Text-Guided Image Editing Dataset
TL;DR: Apple released Pico-Banana-400K, a ~400K sample dataset of (image, instruction, edited image) triplets built from real photos (Open Images). It includes multi-turn sequences and preference data, spans 35 edit types across 8 categories, and is licensed CC BY-NC-ND 4.0 (research-only; no commercial use or derivatives).
Key Facts (skim this)
License: CC BY-NC-ND 4.0 → research-only, no commercial use, no derivatives.
- Scale: ~400,000 triplets (single-turn + multi-turn + preference).
- Source images: Open Images (real photos).
- How edits were made: Apple’s editor Nano-Banana performed edits.
- Curation: automatic quality scoring with a multimodal evaluator; Gemini-2.5 referenced for prompt/write-ups and verification.
- Coverage: 35 edit types grouped into 8 categories (from pixel-level tweaks to object/scene/stylistic changes).
- Special subsets: ~72K multi-turn, ~56K preference (pos/neg) pairs.
What is Pico-Banana-400K?
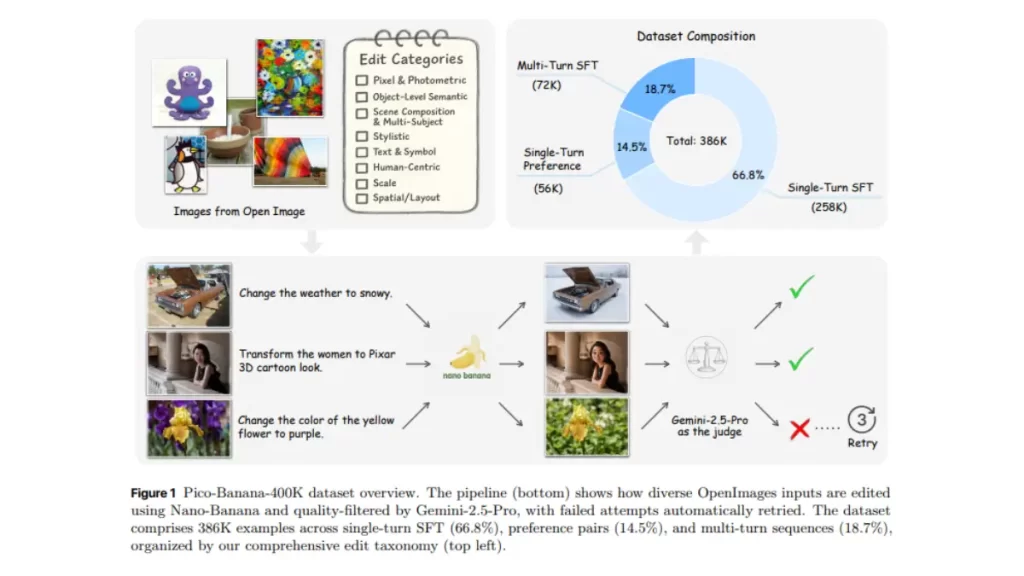
Pico-Banana-400K is Apple’s large-scale dataset for instruction-based image editing. Each example pairs a natural-language edit instruction with a source image and a resulting edited image. Unlike many prior sets that lean heavily on synthetic scenes, this one is built on real photographs, which helps models learn edits that preserve content and realism.
Dataset composition
- Triplet format: (original image, instruction, edited image)
- Counts:
- Single-turn SFT (success cases): ~257K
- Preference data (pos/neg): ~56K
- Multi-turn sequences: ~72K
- Resolution: typically 512–1024px
- Taxonomy:35 edit operations across 8 semantic categories, including:
- Pixel & Photometric (exposure/contrast/white balance)
- Object-level (add/remove/replace/relocate)
- Scene composition (lights/shadows/weather)
- Stylistic (artistic/film looks)
- Text & Symbol (signage, billboards)
- Human-centric (expression/clothing—ethically safe)
- Scale & Perspective (zoom, crop, viewpoint)
- Spatial/Layout (outpainting, framing)
How Apple built and curated it
- Instruction generation: concise, image-aware edit prompts were generated automatically.
- Editing: Nano-Banana (Apple’s internal editor) executed the edits.
- Quality control: an automated MLLM-based judge scored instruction-faithfulness, realism, preservation, and technical quality; only high-scoring results were kept. The pipeline also retains failure cases for preference learning.
- Multi-turn: sequences chain multiple edits to model planning and reasoning over consecutive modifications.
Special subsets (why they matter)
- Long–short instruction pairs: useful for instruction rewriting and summarization (teach the model to follow terse commands without losing fidelity).
- Multi-turn (~72K): train and evaluate sequential editing, planning (e.g., “brighten → remove object → recolor shirt”).
- Preference (~56K): pairwise better/worse signals for alignment, reward-modeling, and RLHF-style fine-tuning.
License: what you can and can’t do
- Allowed: research, benchmarking, academic demos.
- Not allowed: commercial use (training a product model), redistributing derivatives of the dataset.
- Note: source photos inherit Open Images licensing; you must comply with both licenses.
If you’re building a commercial model, either keep this strictly for evaluation or mix in commercially permitted datasets and segregate training runs.
How it compares (quick context)
- HQ-Edit (2024): ~197–200K high-quality pairs curated with GPT-4V + DALL·E-3; strong prompts and alignment metrics, lower scale than Pico-Banana but very clean.
Pico-Banana-400K stands out by mixing real-photo breadth, multi-turn sequences, and preference signals at 400K scale. - InstructPix2Pix (2022): ~450K automatically generated edit pairs (synthetic pipeline with GPT-3 + Stable Diffusion). Great starter set but noisier and less “real-photo anchored.”
- Unlike broadly focused datasets like ImageNet or LAION, which primarily target general image classification or captioning tasks, Pico-Banana-400K exclusively focuses on text-guided image editing. Its unique multi-turn editing sequences and detailed edit taxonomy fill a market gap by enabling research on sequential and interactive image editing features missing in existing datasets.
Practical uses (research-only)
- SFT baseline: train or fine-tune an instruction-following editor on the single-turn split.
- Reward modeling / DPO: use the preference split to teach models what a “better edit” looks like.
- Conversational editor: pretrain on single-turn, then teach multi-step workflows with the multi-turn split.
- Instruction rewriting: use long–short pairs to make models robust to terse or noisy commands.
Limitations & open questions
- Ethics & safety: Human-centric edits should avoid identity manipulation misuse—adhere to clear policy filters.Limitations & open questions
- Ethics & safety: Human-centric edits should avoid identity manipulation misuse—adhere to clear policy filters.
- License constraints: CC BY-NC-ND blocks direct commercialization.
- Evaluator bias: automated judges (any MLLM) can encode systematic preferences; always human-spot-check.
- Domain gaps: Open Images is broad but may under-represent niche scenes or professional studio setups.
- License constraints: CC BY-NC-ND blocks direct commercialization.
- Evaluator bias: automated judges (any MLLM) can encode systematic preferences; always human-spot-check.
- Domain gaps: Open Images is broad but may under-represent niche scenes or professional studio setups.
Technical Innovations in Dataset Creation
Apple’s innovative approach leverages Gemini AI for rigorous automated quality control, screening each image-edit pair for technical precision and instruction compliance. The use of both long-form, elaborate prompts and concise, user-style commands teaches models to work across detailed designer projects and casual user requests. This dual-instruction paradigm supports better natural language comprehension and fluid human-computer interaction, which is especially valuable for real-world applications.

Future Research Opportunities
This dataset unlocks avenues for advanced multimodal models, sequential “chain-of-edit” reasoning, and reward-model fine-tuning. The granular taxonomy and multi-turn sequences provide rich context for research into iterative image manipulation and AI planning. As future releases of GPT-4o, Stable Diffusion, or Apple’s own AI systems arrive, Pico-Banana-400K will serve as a vital training and benchmarking resource.
Competitive Analysis: Why Outrank Other Datasets?
Compared to ImageNet, LAION, and DiffEdit, Pico-Banana-400K offers unmatched specificity for edit instructions, realism in image sources, and human-centric guidance. Its focus on text-guided editing transcends the limitations of traditional classification and captioning datasets, positioning it as the go-to foundation for next-generation AI-driven editing research.
Dataset Accessibility and Licensing
Researchers and engineers can access the Pico-Banana-400K dataset directly via GitHub. It’s freely available for non-commercial research, subject to Apple’s licensing terms. The project’s open structure encourages contributions, potential extensions, and adaptation for other visual domains making it fertile ground for community-driven innovation.
FAQ
What is Pico-Banana-400K?
A ~400K dataset of real-image edit triplets for instruction-guided image editing, with multi-turn and preference subsets.
Is it free for commercial use?
No. It’s CC BY-NC-ND 4.0: research-only, no commercial use, no derivatives.
How is it different from InstructPix2Pix or HQ-Edit?
More real-photo grounding and task richness (multi-turn + preference) at larger scale; HQ-Edit is smaller but very high quality; InstructPix2Pix is larger-ish but more synthetic.
Can I train a product model on it?
Not directly. Use it for evaluation or mix with permissive datasets and keep training runs license-segregated.
Conclusion
Pico-Banana-400K significantly advances the frontier of AI image editing by providing a large-scale, meticulously curated dataset with unique features that support sophisticated, instruction-based photo manipulation research. For non-commercial research purposes, the dataset is openly accessible on GitHub, offering a valuable resource for the AI community to foster innovation and enhanced model capabilities.
This dataset marks a pivotal development for AI researchers and developers aiming to create the next wave of intelligent, text-guided photo editing tools.
Leave a Reply